Frequentist Inference Case Study - Part B¶
Learning objectives¶
Welcome to Part B of the Frequentist inference case study! The purpose of this case study is to help you apply the concepts associated with Frequentist inference in Python. In particular, you'll practice writing Python code to apply the following statistical concepts:
- the z-statistic
- the t-statistic
- the difference and relationship between the two
- the Central Limit Theorem, including its assumptions and consequences
- how to estimate the population mean and standard deviation from a sample
- the concept of a sampling distribution of a test statistic, particularly for the mean
- how to combine these concepts to calculate a confidence interval
In the previous notebook, we used only data from a known normal distribution. You'll now tackle real data, rather than simulated data, and answer some relevant real-world business problems using the data.
Hospital medical charges¶
Imagine that a hospital has hired you as their data scientist. An administrator is working on the hospital's business operations plan and needs you to help them answer some business questions.
In this assignment notebook, you're going to use frequentist statistical inference on a data sample to answer the questions:
- has the hospital's revenue stream fallen below a key threshold?
- are patients with insurance really charged different amounts than those without?
Answering that last question with a frequentist approach makes some assumptions, and requires some knowledge, about the two groups.
We are going to use some data on medical charges obtained from Kaggle.
For the purposes of this exercise, assume the observations are the result of random sampling from our single hospital. Recall that in the previous assignment, we introduced the Central Limit Theorem (CLT), and its consequence that the distributions of sample statistics approach a normal distribution as $n$ increases. The amazing thing about this is that it applies to the sampling distributions of statistics that have been calculated from even highly non-normal distributions of data! Recall, also, that hypothesis testing is very much based on making inferences about such sample statistics. You're going to rely heavily on the CLT to apply frequentist (parametric) tests to answer the questions in this notebook.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import t
from numpy.random import seed
medical = pd.read_csv('insurance2.csv')
medical.shape
medical.head()
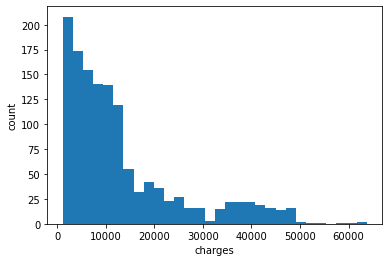
Q1: Plot the histogram of charges and calculate the mean and standard deviation. Comment on the appropriateness of these statistics for the data.
A:
plt.hist(medical['charges'],bins='auto')
plt.xlabel('charges')
plt.ylabel('count');
medical.describe().T
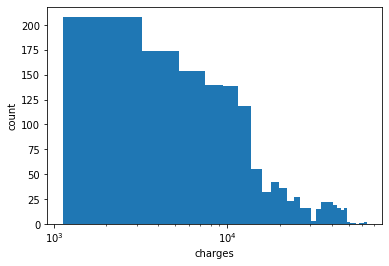
The distribution of charge is right-skewed. This can be confirmed visually from the histogram and the difference between mean and median. It may be more appropriate to use logistic axis.
plt.hist(medical['charges'],bins='auto');
plt.xscale('log')
plt.xlabel('charges')
plt.ylabel('count');
Q2: The administrator is concerned that the actual average charge has fallen below 12,000, threatening the hospital's operational model. On the assumption that these data represent a random sample of charges, how would you justify that these data allow you to answer that question? And what would be the most appropriate frequentist test, of the ones discussed so far, to apply?
A:
Because the sampling method is randam sampling, the internal validity of the study population is effective. However, sample population is only from the hospital, target population that external validity will be effective is only this hospital.
The appropriate test is t-test as we do not know population distribution.
Q3: Given the nature of the administrator's concern, what is the appropriate confidence interval in this case? A one-sided or two-sided interval? (Refresh your understanding of this concept on p. 399 of the AoS). Calculate the critical value and the relevant 95% confidence interval for the mean, and comment on whether the administrator should be concerned.
A:
The appropriate confidence interval in this case is one-sided interval as the null hopothesis H0 is violated only when any part of confidence interval is 12,000 or less.
def t_test(sample):
# 100% - 95% = 5%
alpha = 0.05
# degree of freedom
sampleSize = len(sample)
dof = sampleSize - 1
# probability percentile function for t
t_ = t.ppf(1-alpha/2,dof)
# ref:
# https://www.statisticshowto.com/probability-and-statistics/confidence-interval/
# Unbiased estimate of population variance
# (sample standard deviation)
sampleStd = np.std(sample,ddof=1)
# Standard Error
SE = sampleStd/np.sqrt(sampleSize)
# CI with sample std
MOEt = t_ * SE
# sample mean
m = np.mean(sample)
# print(sampleStd,population_std)
return t_,sampleStd,SE,MOEt,m
# Calculate the 95% Confidence Interval of the mean
# (== CI)
t_,sampleStd,SE,MOEt,m = t_test(medical['charges'])
print('H0 : 12000 <= sample mean,\
\nH1: 12000 > sample mean,\
\nalpha=0.05\n')
print(f'Unbiased estimate of population variance = {sampleStd}')
print(f'Satandard Error = {SE}')
# print('\nt-test')
# print(f't value = {(m-population_m) / SE}')
print(f't0 = {t_}')
print(f'\nMOE with t-test is {round(MOEt,2)}')
print(f'\nConfidence intervals for the mean: (lower,upper) = \n{m-MOEt,m+MOEt}')
print(f'\nIs H0 true? => {12000 <= m-MOEt}')
_ = plt.hist(sample, bins='auto')
_ = plt.xlabel('charges')
_ = plt.ylabel('count of charges')
_ = plt.title('Distribution of charges in our hospital')
_ = plt.axvline(m, color='b')
_ = plt.axvline(m+MOEt, color='b', linestyle='--')
_ = plt.axvline(m-MOEt, color='b', linestyle='--')
_ = plt.axvline(12000, color='r')

In conclusion, with 95% of confidence, it is not likely that actual average charge is below 12,000. Therefore, the administrator should not be concerned.
The administrator then wants to know whether people with insurance really are charged a different amount to those without.
Q4: State the null and alternative hypothesis here. Use the t-test for the difference between means, where the pooled standard deviation of the two groups is given by: \begin{equation} s_p = \sqrt{\frac{(n_0 - 1)s^2_0 + (n_1 - 1)s^2_1}{n_0 + n_1 - 2}} \end{equation}
and the t-test statistic is then given by:
\begin{equation} t = \frac{\bar{x}_0 - \bar{x}_1}{s_p \sqrt{1/n_0 + 1/n_1}}. \end{equation}(If you need some reminding of the general definition of t-statistic, check out the definition on p. 404 of AoS).
What assumption about the variances of the two groups are we making here?
A:
We assume that the variance of the two groups are same.
H0(Null): The mean of charge for people with insurance = The mean of charge for people without insurance
H1(Alternative): The mean of charge for people with insurance != The mean of charge for people without insurance
Q5: Perform this hypothesis test both manually, using the above formulae, and then using the appropriate function from scipy.stats (hint, you're looking for a function to perform a t-test on two independent samples). For the manual approach, calculate the value of the test statistic and then its probability (the p-value). Verify you get the same results from both.
A:
medical.insuranceclaim.isna().sum()
s1 = medical[medical.insuranceclaim==1]
s0 = medical[medical.insuranceclaim==0]
# The pooled standard deviation of the two groups: sp
sp=np.sqrt(((len(s1.charges)-1)*(np.std(s1.charges,ddof=1)**2) + (len(s0.charges)-1)*(np.std(s0.charges,ddof=1)**2))/(len(s1.charges)+len(s0.charges)-2))
sp
# t-test statistic
t2_=(np.mean(s1.charges) - np.mean(s0.charges))/(sp*np.sqrt((1/len(s1.charges))+(1/len(s0.charges))))
t2_
# % of confidence: p
dof=len(s1.charges)+len(s0.charges)-2
pvalue=2*t.cdf(-t2_,dof)
pvalue
Terminology
import scipy
scipy.stats.ttest_ind(s1.charges, s0.charges,equal_var=True)
Congratulations! Hopefully you got the exact same numerical results. This shows that you correctly calculated the numbers by hand. Secondly, you used the correct function and saw that it's much easier to use. All you need to do is pass your data to it.
Q6: Conceptual question: look through the documentation for statistical test functions in scipy.stats. You'll see the above t-test for a sample, but can you see an equivalent one for performing a z-test from a sample? Comment on your answer.
A:
No, there isn't.
Learning outcomes¶
Having completed this project notebook, you now have good hands-on experience:
- using the central limit theorem to help you apply frequentist techniques to answer questions that pertain to very non-normally distributed data from the real world
- performing inference using such data to answer business questions
- forming a hypothesis and framing the null and alternative hypotheses
- testing this using a t-test